
一切都要從,幫忙一位朋友進行資料前處理開始說起。要處理的資料數量超過2000萬筆,以目前電腦處理速度來說,算不上「大數據」,不過對於一台記憶體只有32G、CPU應該是4-6核心的電腦來說,夠了。尤其欄為數量來說,恐怕超過千個。這讓即使使用了NumPy,像下面這樣要去過濾資料也夠了....
for d in df:
result = d[d>0]
用df[df>0]會GG...直接榨給你看 。所以對於一個二維矩陣,只能一筆資料一筆資料處理...可是光是處理一筆資料就需要花上12、13秒,這...要花上幾年時間...。好,來等吧!怎麼可能!!
。所以對於一個二維矩陣,只能一筆資料一筆資料處理...可是光是處理一筆資料就需要花上12、13秒,這...要花上幾年時間...。好,來等吧!怎麼可能!!
在看看CPU使用率...14%?大可同時跑六七個執行去。看點範例先來試試看:
"""# 引入`multiprocessing`"""
from multiprocessing import Pool, cpu_count
"""# 定義要多次執行的函式"""
def f(x):
return x*x
"""## 多執行緒實行"""
with Pool(cpu_count()) as p:
print(p.map(f, [1, 2, 3]))
"""# 後續工作"""
print("Hello")
完美,按下執行... 死了??
死了??
我嘗試在命令提示字元(CMD)去執行Python,然後運行同樣的程式碼...同樣會GG。
Tensorflow會運行多執行緒,甚至可以在多台機體上,協調工作。Jupyter Notebook也是最為流行的工具之一,在Colab上也會發生同樣的事?怎麼可能!
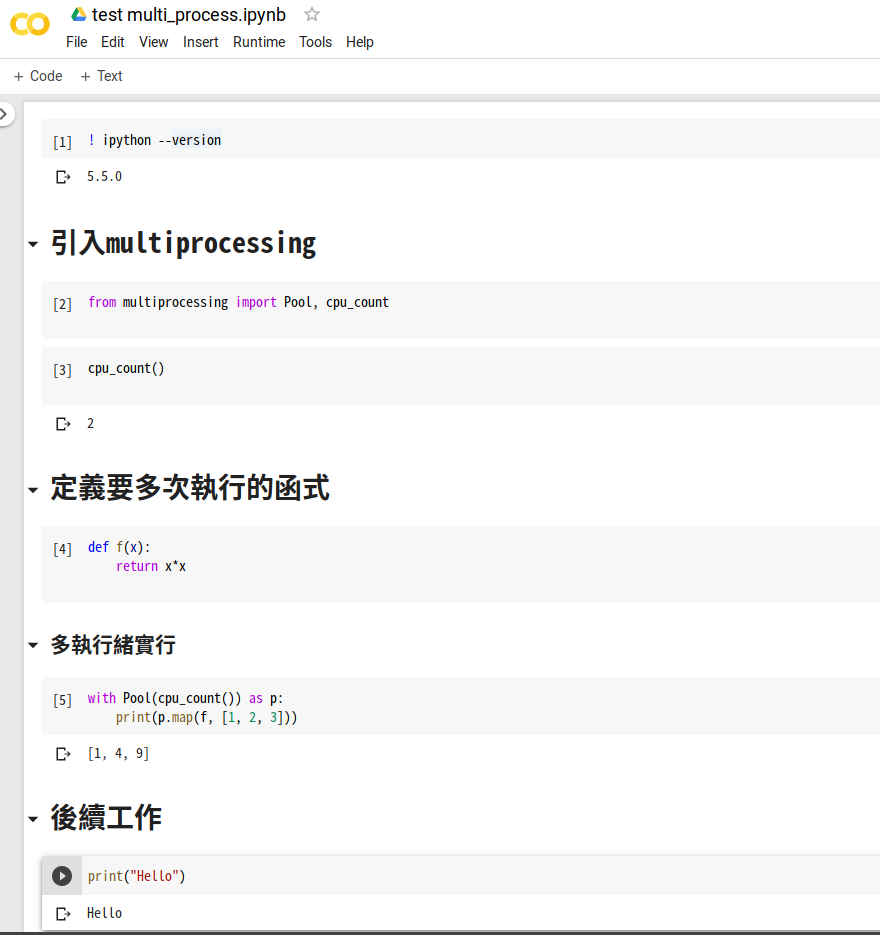
 沒問題阿?!
沒問題阿?!
可能Google有把Colab做過優化...沒設定就會出錯,來拿自己的環境下去試試:
環境
也沒問題阿!
可...這問題好像不算太少發生ㄟ?
看最後一個,有可能是作業系統的問題,但沒辦法排除與IPython版本有關。Windows似乎有其他方式解決,但也許未來Jupyter Notebook在Windows上也會有更好的支援。
對了,上面的筆記本,可以在這裡找到。

 iThome鐵人賽
iThome鐵人賽